昨天我們嘗試動手刻了一個神經網路,準確度雖然看似很高了,但似乎還有進步的空間,今天我們就來介紹如何優化我們的神經網路。
在優化前我們要先搞清楚,要優化神經網路的哪個部分,那就必須知道什麼樣的神經網路是好的,一般來說評估標準有以下三點:
準確度自然不用多說,我們當然希望模型預測的答案越準越好,而推論速度是指模型預測出答案的時間,在一些實務上(自動駕駛),我們需要模型在短時間內就給出預測值,這時候推論速度就很重要,而模型大小則會影響神經網路在一些邊緣裝置上的應用,例如架設攝影機辨識路人有沒有戴口罩,我們不可能搬一台電腦到路上,就要應用一些邊緣裝置,像是Jetson Nano。
具體該優化哪個指標,其實還是要看我們面對什麼樣的問題,假如是自動駕駛要感應周圍有沒有障礙物,推論速度就是一個很重要的指標;假如是要找出潛在的信用卡盜刷交易,那麼準確度就是重要的指標,先了解該追求哪項指標,再去優化自己的神經網路模型,下面我們開始介紹有哪些優化方法。
對資料集的優化通常是最有效的辦法,尤其是對於準確率的提升,能擁有一個好的資料集比其他模型超參數的優化來的重要許多,資料集優化主要有以下幾項:
這部分我們在前面的章節有詳細的介紹過,大家可以回去看這篇。
調參的部分也是在打比賽中一個很重要的優化過程,有人說神經網路內部的訓練過程就像一個黑盒子,我們無法得知他的計算過程,因此只能透過調整參數的方式去嘗試更好的組合,下面我們就來介紹一些超參數以及調整方式:
每個訓練批次所提取的資料數,通常我們會設定比目標類別還要多一些,才能確保每次訓練都會抽到不同標籤的樣本,但批次大小也不太能隨意調整,需考慮自身設備的記憶體大小,若批次太大可能會跑不動。
神經網路訓練的次數,當你發現模型訓練的準確度不斷上升時,就可以調高訓練的輪次,讓模型繼續收斂,反之模型如果一直沒有進步,就要將降低訓練的輪次
學習率是控制梯度下降的參數,學習率過大會導致模型找不到局部最佳解;而學習率過小則會造成收斂速度過慢,且會被困在局部最佳解的點,無法找到全局最佳解,一般來說會設定0.01,但要隨時根據不同情況做調整。
最好的方法是設置"動態學習率",在模型隨著訓練次數的增加去調整它的學習率,當梯度下降較快時,增加學習率,而當梯度趨於平緩時就降低學習率,下面的程式碼範例可根據不同情況做調整。
#設置動態學習率
from tensorflow.keras.callbacks import ReduceLROnPlateau
LR_function=ReduceLROnPlateau(monitor='val_acc',
patience=5,
# 5 epochs 內acc沒下降就要調整LR
verbose=1,
factor=0.5,
# LR降為0.5
min_lr=0.00001
# 最小 LR 到0.00001就不再下降
)
最佳化方法有很多種,最常見的就是隨機梯度下降(SGD),其他還有像是Adagrad、RMSProp、Adam...等多種方法,模型都可以嘗試去套套看,Keras中也有支援,只需簡單的程式碼即可使用。
#SGD
tf.keras.optimizers.SGD(
learning_rate=0.01, momentum=0.0, nesterov=False, name='SGD', **kwargs
)
#Adagrad
tf.keras.optimizers.Adagrad(
learning_rate=0.001, initial_accumulator_value=0.1, epsilon=1e-07,
name='Adagrad', **kwargs
)
#RMSProp
tf.keras.optimizers.RMSprop(
learning_rate=0.001, rho=0.9, momentum=0.0, epsilon=1e-07, centered=False,
name='RMSprop', **kwargs
)
#Adam
tf.keras.optimizers.Adam(
learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=False,
name='Adam', **kwargs
)
除了參數的調整,我們也可以對整個網路模型進行一些優化方法。
這是Google提出的一種正規化技術,用來防止過度擬合的問題,其作法是在神經網路的某些層中,隨機丟棄部分的神經元,如此可避免在訓練的過程中有過多的神經元產生複雜的相互適應,讓剩下的神經元在更新資訊後更強健,作法如下:
input_shape = (128, 128, 3)
# 建立簡單的線性執行的模型
model = Sequential()
# 建立卷積層
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape,
padding="same"))
# 建立卷積層
model.add(Conv2D(64, (3, 3), activation='relu',padding="same"))
# 建立池化層,池化大小2x2,取最大值
model.add(MaxPooling2D(pool_size=(2, 2)))
# Dropout層隨機斷開輸入神經元,用於防止過度擬合,斷開比例:0.25
model.add(Dropout(0.25))
# Flatten層把多維的輸入一維化,常用在從卷積層到全連接層的過渡。
model.add(Flatten())
# 全連接層: 128個output
model.add(Dense(128, activation='relu'))
# Dropout層隨機斷開輸入神經元,用於防止過度擬合,斷開比例:0.5
model.add(Dropout(0.5))
# 使用 softmax activation function,將結果分類
model.add(Dense(num_classes, activation='softmax'))
這個技巧主要是為了使模型變小,其原理為去除神經網路中冗餘的參數,使得模型大小縮減、運算速度提高,有點類似Dropout,但Pruning是對已訓練完成或套用其他權重的模型使用。這個做法稍微有些複雜,但Tensorflow有好心的提供範例,小編在此附上連結大家可以去參考。
目前大多數的神經網路模型在訓練即推論時都是使用FP32的精度(32位元浮點數),而我們可以透過咿些轉換的方法將精度調降為FP16或是int8,如此一來其運算速度可以倍數成長,但精度調整就像一把雙面刃,調整時會造成資訊的流失,準確度也會隨之降低,因此要決定出一個好的平衡點,再去使用這個方法,TensorRT有提供轉換教學,網址如下:
TFLite是Tensorflow提供的一種架構,其價值在於將神經網路部屬到一些微型裝置,透過轉換、壓縮等功能可以降低模型的大小、提升模型的推論速度。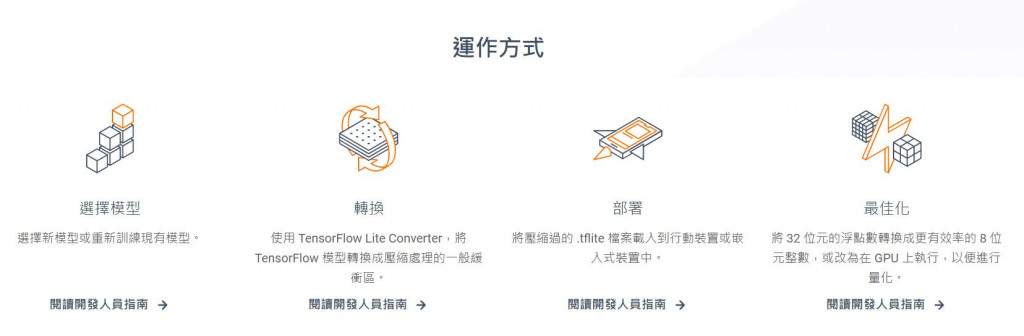
篇幅的關係我這邊就不詳細介紹了,一樣附上網址:
今天介紹了一些優化神經網路的方法,最後想要提醒大家的是,儘管優化方法有很多,但不代表我們用了很多方法加到模型裡,我們的模型就會變得多厲害,也不是一次把所有方法加上去就好,調參時要有耐心的慢慢嘗試每種方法,找到一個最適合模型的組合。
明天我們將介紹另一種常見的優化方法-使用預訓練模型,敬請期待吧!


 iThome鐵人賽
iThome鐵人賽